
本文将不具体讲述JVM的机制,重点关注JVM有哪些可以调优的参数,这些参数对JVM又有哪些影响
一、调优方向参考表
| 调优方向 | 需求指标 | 指标情况 |
|---|---|---|
| 1.垃圾回收算法设置是否合理 | 1.年轻代回收算法 2.老年代回收算法 3.需从并发并行及本身回收策略两个方向考虑 |
吞吐量优先:并行 响应时间优先:并发 |
| 1.1垃圾回收时间是否合理 | 1.young gc时间与次数 2.old gc时间与次数 |
吞吐量优先:单次时间可以略长 响应时间优先:gc时间需严格把控 |
| 2.各代划分是否合理 | 1.堆大 小 2.年轻代大小:E区及S区分配比例或大小 3.老年代=总堆-年轻代大小 4.持久代大小 |
吞 吐 量 优 先:堆大小↑年轻↑老年↓ 响应时间优先:堆大小↓年轻↑老年↓ |
| 3.新生代迁移到老年代花费时间是否合理 | 1.年轻代迁移到老年代的频率 2.迁移时间 |
|
| 4.1内存是否存在泄露 | 1.当前堆大小 2.堆使用情况 |
在总堆大小不变的情况下,若堆使用情况在两次GC前后有增长,则初步判定会有内存泄露风险 |
| 4.2 | 是否抛出java.lang.OutOfMemoryError: PermGen space异常 | 由于Perm区被占满,此时需增大Perm区大小 |
| 4.3 | 是否抛出java.lang.StackOverflowError异常 | 存载递归没有返回,或者循环调用现象 |
| 4.4 | 是否抛出Fatal: Stack size too small异常 | 线程池存载瓶颈,增大线程栈大小或进一步定位代码部分 |
| 4.5 | 是否抛出java.lang.OutOfMemoryError: unable to create new native thread异常 | 系统资源不足以创建线程 1.降低JVM总内存资源占用 2.降低-Xss线程栈大小 3.减少总体线程数量 |
| 5.堆内类、对象状态是否合理 | 1.类数量 2.对象数量 3.对象总大小 |
1.判断类数量波动是否合理 2.对象数量波动是否合理 3.对象总大小是否合理 |
| 6.线程状态是否合理 | 1.系统线程数量 2.系统线程状态 3.线程栈大小 |
1.判断线程数量波动、线程总体状态是否合理 2.吞吐优先:线程栈大小↓ |
| 7.系统是否存在大量短命大对象 | 1.年轻代大小 2.对象数量 |
若年轻代增长浮动较快,而对象数量增长缓慢,则存在大量短命大对象 1.通过设定XX:PetenureSizeThreshold值使大对象直接进去老年代 |
| 8.当前进入老年代的年龄是否合理 | 1.当前进入老年代年龄的设定(默认为15) | JVM会动态判断当前进入老年代的年龄,选择最小的年龄进行转移,所以-XX:MaxTenuringThreshold不宜设置较小 |
二、调优详细步骤
1.垃圾回收算法设置是否合理
使用jmap -heap pid查看当前堆信息,结果如下,第七行显示的则为垃圾回收算法1
2
3
4
5
6
7
8
9
10[root@root Desktop]# jmap -heap 3597
Attaching to process ID 3597, please wait...
Debugger attached successfully.
Client compiler detected.
JVM version is 25.151-b12
using thread-local object allocation.
Mark Sweep Compact GC
····
····
分析指南
| 垃圾回收算法 | 说明 |
|---|---|
| Serial GC(Mark Sweep Compact GC) | 1.新生代串行,老年代串行 2.新生代复制,老年代标记压缩 |
| ParNew GC | 1.新生代并行,老年代串行 2.新生代复制,老年代标记压缩 |
| Parallel GC(throughput GC) | 1.新生代并行,老年代串行 2.新生代复制,老年代标记压缩 3.更关注吞吐量,可以打开自适应调节 |
| Parallel Old GC | 1.新生代并行,老年代并行 2.新生代复制,老年代标记、汇总、压缩 |
| ConcMarkSweepGC(CMS GC) | 1.新生代并行,老年代并发 2.新生代复制,老年代算法更加复杂 3.更加关注响应时间 |
| G1 GC | 1.前沿成果,目标替换CMS 2.尚不稳定 |
| 策略 | 优点 | 缺点 |
|---|---|---|
| 串行收集 | 效率比较高,适用单处理器机器 | 无法使用多处理器的优势 |
| 并行收集 | 1.吞吐量优先 2.CPU数目越多,速度越快 |
GC时会暂停整个系统 |
| 并发收集 | 1.响应时间优先 2.回收时暂停系统时间最短 |
1.算法复杂性大 2.系统处理能力降低(占用更多的内存和CPU) 3.碎片问题无法有效解决 |
1.1垃圾回收时间是否合理
1 | [root@root Desktop]# jstat -gc 3597 |
分析指南:使用YGCT/YGC得到每次young gc时间,使用FGCT/FGC得到每次Full gc时间。吞吐量优先:单次时间可以略长,响应时间优先:gc时间需严格把控。
#####2.各代划分是否合理
重点关注年轻代和老年代的合理分配。永久代和元空间的争议将在4.2中体现
通过Jinfo指令查看各代划分信息1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17[root@root Desktop]# jinfo -flag MaxHeapSize 3597 //查看堆最大值
-XX:MaxHeapSize=268435456
[root@root Desktop]# jinfo -flag InitialHeapSize 3597 //查看堆默认值
-XX:InitialHeapSize=16777216
[root@root Desktop]# jinfo -flag MaxNewSize 3597 //查看新生代最大值
-XX:MaxNewSize=89456640
[root@root Desktop]# jinfo -flag NewRatio 3597 //老年代÷新生代值
-XX:NewRatio=2
[root@root Desktop]# jinfo -flag SurvivorRatio 3597 //eden区÷s区的值
-XX:SurvivorRatio=8
[root@root Desktop]# jinfo -flag TargetSurvivorRatio 3597 //S区可使用率
-XX:TargetSurvivorRatio=50
| 指标 | 说明 |
|---|---|
| MaxHeapSize (堆最大值) | gc时间和对堆大小成反比(堆越大,gc时间越长) 1.吞吐量优先时设置为可用内存的80% 2.响应时间优先时动态调整 |
| InitialHeapSize(堆初始大小) | 建议和最大值相同,减少扩容的性能影响 |
| MaxNewSize(新生代最大值,老年代=堆大小-新生代) | 结合full gc前后年轻代和老年代的状态进行设置,一般来说新生代大小尽量设置一个较大值,减少老年代大小 |
| NewRatio(老年代÷新生代比值) | 参考↑ |
| SurvivorRatio(eden区÷s区的值) | 结合每次young gc前后进入s区的增长值和设置的最大年龄进行调整 |
| TargetSurvivorRatio(S区可使用率) | 默认50%,过小时新生代的对象会过早的进入老年代 |
3.新生代迁移到老年代花费时间是否合理
启动时设置-verbosegc打印gc日志,常用配合参数1
2
3
4
5-XX:+PrintGCDetails,打印GC信息,这是-verbosegc默认开启的选项
-XX:+PrintGCTimeStamps,打印每次GC的时间戳
-XX:+PrintHeapAtGC:每次GC时,打印堆信息
-XX:+PrintGCDateStamps (from JDK 6 update 4) :打印GC日期,适合于长期运行的服务器
-Xloggc:/home/admin/logs/gc.log:制定打印信息的记录的日志位置
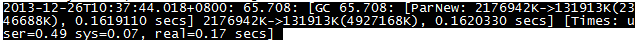
1
2
3
4
5
6
7
8
9
10time:执行GC的时间,需要添加-XX:+PrintGCDateStamps参数才有;
collector:minor gc使用的收集器的名字。
starting occupancy1:GC执行前新生代空间大小。
ending occupancy1:GC执行后新生代空间大小。
total occupancy1:新生代总大小
pause time1:因为执行minor GC,Java应用暂停的时间。
starting occupancy3:GC执行前堆区域总大小
ending occupancy3:GC执行后堆区域总大小
total occupancy3:堆区总大小
pause time3:Java应用由于执行堆空间GC(包括full GC)而停止的时间。
根据日志结果,统计young gc前后,s区中的对象进入老年代所花费的时间,判断是否合理(一般情况下不需要关注此指标)
4.1内存是否存在泄露
4.1.1-verbosegc日志打开
观察每次gc后已使用堆的大小,若在堆总量不变的情况下仍持续增长,则初步判定存在内存泄露风险
4.1.2-verbosegc未打开
通过jstat -gc pid显示当前gc情况,已使用堆大小=S0U+S1U+EU+OU,若在S0C+S1C+EC+OC不变的情况下,每次GC后持续增长,则初步判定存在内存泄露风险1
2
3[root@root Desktop]# jstat -gc 3597
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
5376.0 5376.0 0.0 2553.2 43584.0 4109.4 108536.0 70620.4 44056.0 43357.1 0.0 0.0 267 3.368 10 0.652 4.021
4.2内存是否存在泄露
- 查看日志中是否抛出java.lang.OutOfMemoryError: PermGen space异常
- 通过jinfo查看perm区大小(JVM1.6前存在此设置),查看永久代大小是否合理,若应用内动态生成或者调用class时,例如Hibernate时,需要设置较大
1
2[root@root Desktop]# jinfo -flag MaxPermSize 3597
no such flag 'MaxPermSize'
4.3内存是否存在泄露
- 查看日志是否抛出java.lang.StackOverflowError异常
- 此异常问题原因为存在递归没有返回,或者循环调用现象,通过jmap指令导出堆信息进行排查
1
2
3[root@root ~]# jmap -dump:format=b,file=/usr/jmap_20171221.hprof 5248
Dumping heap to /usr/jmap_20171221.hprof ...
Heap dump file created
4.4内存是否存在泄露
- 查看日志是否抛出java.lang.StackOverflowError异常
- 问题原因在于JVM线程占用内存过多,系统没有足够的资源用于创建线程
解决方式1:减少JVM内存占用1
2
3
4
5
6
7
8
9
10
11
12
13
14[root@root Desktop]# jinfo -flag MaxHeapSize 3597 //查看堆最大值
-XX:MaxHeapSize=268435456
[root@root Desktop]# jinfo -flag InitialHeapSize 3597 //查看堆默认值
-XX:InitialHeapSize=16777216
[root@root Desktop]# vmstat -s //查看系统当前剩余内存
···
···
800804 free memory
···
···
//查看系统内存是否足够
此可以观察到的现象为:系统内存可使用量很低,所以降低堆最大值和默认值即可
解决方式2:降低单个线程栈的大小1
2[root@root Desktop]# jinfo -flag ThreadStackSize 3597 //查看当前单个线程栈大小
-XX:ThreadStackSize=320
解决方式3:降低线程的数量
JVM无法通过具体指标控制线程数量,线程数受堆最大值和单个线程栈大小影响,同时受系统可开最大线程数限制1
2
3
4
5
6
7
8
9
10
11[root@root Desktop]# jinfo -flag MaxHeapSize 3597 //查看堆最大值
-XX:MaxHeapSize=268435456
[root@root Desktop]# jinfo -flag ThreadStackSize 3597 //查看当前单个线程栈大小
-XX:ThreadStackSize=320
[root@root Desktop]# cat /proc/sys/kernel/threads-max //查看系统可开最大线程数
32341
[root@root Desktop]# cat /proc/sys/kernel/pid_max //查看系统最大pid数
32768
1.类数量
2.对象数量
3.对象总大小
1.判断类数量波动是否合理
2.对象数量波动是否合理
3.对象总大小是否合理
5.堆内类、对象状态是否合理
1 | [root@root Desktop]# jstat -class 5248 //查看堆内类大小数量及大小 |
分析指南:分析堆内类数量、大小、对象数量、对象大小曲线。一般在压测开始一段时间后,都不会出现持续增长的现象。
6.线程状态是否合理
1 | [root@root Desktop]# top -Hp 3597 -n 1| grep 'Tasks' //查看3597进程下线程的状态 |
分析指南:根据压测情况,分析线程总数、执行数、睡眠数、停止数、僵尸数。
7.系统是否存在大量短命大对象
1 | [root@root Desktop]# jmap -histo:live 3597 | grep 'Total' //查看堆内对象数量及大小 |
分析指南:生成对象数量、对象总大小、S0U+S1U+EU的曲线图,如果观察到年轻代增长浮动较快,而对象数量增长缓慢,则初步判定存在短命大对象,通过设定XX:PetenureSizeThreshold值使大对象直接进去老年代
8.当前进入老年代的年龄是否合理
1 | [root@root Desktop]# jinfo -flag MaxTenuringThreshold 3597 //查看当前进入老年代的年龄 |
分析指南:获取YGC的次数、了解young gc前后每次S区的增长幅度,若每次增长10M,S区大小为200M,则年龄为15是一个合理的值;如果每次young gc S区增长50M而S区为200M,则需要增大S区的大小。
9.CPU高
JVMCPU较高没有合适的监控方式,测试时我们要根据测试情况进行定位
- 使用ps指令查看进程内占用CPU较高的线程号
1
2
3
4
5
6
7[root@root Desktop]# ps p 3597 -L -o pcpu,pid,tid,time,tname,cmd
%CPU PID TID TIME TTY CMD
0.0 3597 3597 00:00:00 ? /usr/local/jdk_1.8/jdk1.8.0_151/bin/java -Djava.util.logging.config
0.0 3597 3598 00:00:01 ? /usr/local/jdk_1.8/jdk1.8.0_151/bin/java -Djava.util.logging.config
0.2 3597 3599 00:03:00 ? /usr/local/jdk_1.8/jdk1.8.0_151/bin/java -Djava.util.logging.config
0.0 3597 3600 00:00:01 ? /usr/local/jdk_1.8/jdk1.8.0_151/bin/java -Djava.util.logging.config
···
2.打印CPU占用高的线程的16进制的线程号(在后面会用到)1
2[root@root Desktop]# printf "%x\n" 7363
1cc3
- 通过jstack指令初步定位问题原因
1
2[root@root Desktop]# jstack 3597 | grep 1cc3
"http-bio-8080-exec-140" #193 daemon prio=5 os_prio=0 tid=0xa25da800 nid=0x1cc3 waiting on condition [0x9f34c000]
三、永久区与元空间
JDK 1.8后HotSpot中已经没有PermGen space这个概念,取而代之是一个叫做 Metaspace(元空间) 的东西。
区别在于:元空间的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。1
2
3
4[root@root Desktop]# jinfo -flag MetaspaceSize 3597
-XX:MetaspaceSize=12582912
[root@root Desktop]# jinfo -flag MaxMetaspaceSize 3597
-XX:MaxMetaspaceSize=4294963200
指标分析:元空间的调优和perm区类似,具体可以参考4.2,只是抛出的异常变为java.lang.OutOfMemoryError: Metaspace
四、参考:
后续补充:
- 堆和栈大小 留出来1-2G的大小
- XMN配置为3/8
- 持久代配置成一样的
- xss不要超过512K
- cms new
1 | [^-^]:#### 调优详细步骤 |