
title: python爬虫CCTV2《环球财经连线》
toc: true
date: 2018-09-20 17:35:16
tags:
- python
- 爬虫
categories: 开发
笔者前言:平时比较喜欢看CCTV2的《国际财经报道》(原环球财经连线),但是央视的app没有提供缓存功能,笔者又想上下班和跑步的时候看或者听。于是花了大概一天时间写了python脚本爬取了央视的视频并转为音频。
相关文件下载地址:
一、爬取视频
1. 分析视频链接
通过对央视的cctv2直播和国际财经报道专题页面视频流的传递分析,最终选择了专题页面的视频接口,作为视频下载的爬虫接口。

直播视频接口的分析不作介绍,感兴趣的读者可以自行分析。详细讲解专题页面的视频接口分析
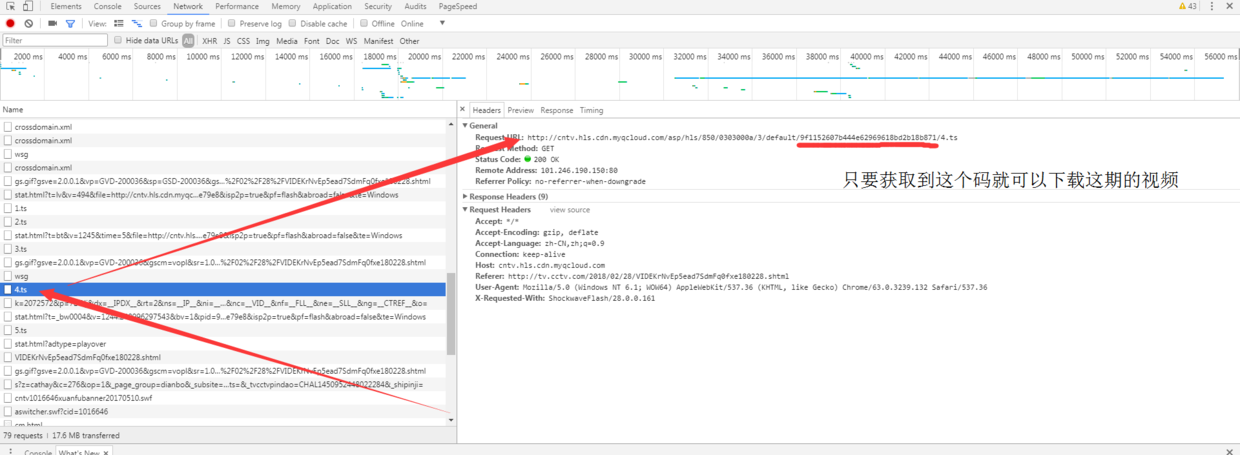
- 通过谷歌浏览器的网络查看器,可以观察到视频接口为
http://cntv.hls.cdn.myqcloud.com/asp/hls/850/0303000a/3/default/9f1152607b444e62969618bd2b18b871/4.ts
可以分析到:整期视频被分成了一个又一个.ts视频,每个.ts视频文件里有10-15秒的节目内容。关键参数为9f1152607b444e62969618bd2b18b871 #每期节目都会有一个对应的节目码1.ts #用于控制播放时间的.ts文件名
这样我们只要可以拿到节目码然后依序下载.ts文件就可以了
获取节目码
翻看之前的请求,在当前页面的请求:http://tv.cctv.com/2018/02/28/VIDEKrNvEp5ead7SdmFq0fxe180228.shtml中,找到了我们需要的节目码(由于笔者是性能测试工程师,所以借用Loadrunner的关联技术很快就找到了节目码所在的位置,算是野路子;正经的情况可能要一个一个请求的翻查,是一个需要经验和耐心的过程。)fo.addVariable("videoCenterId","9f1152607b444e62969618bd2b18b871"); #保存关键字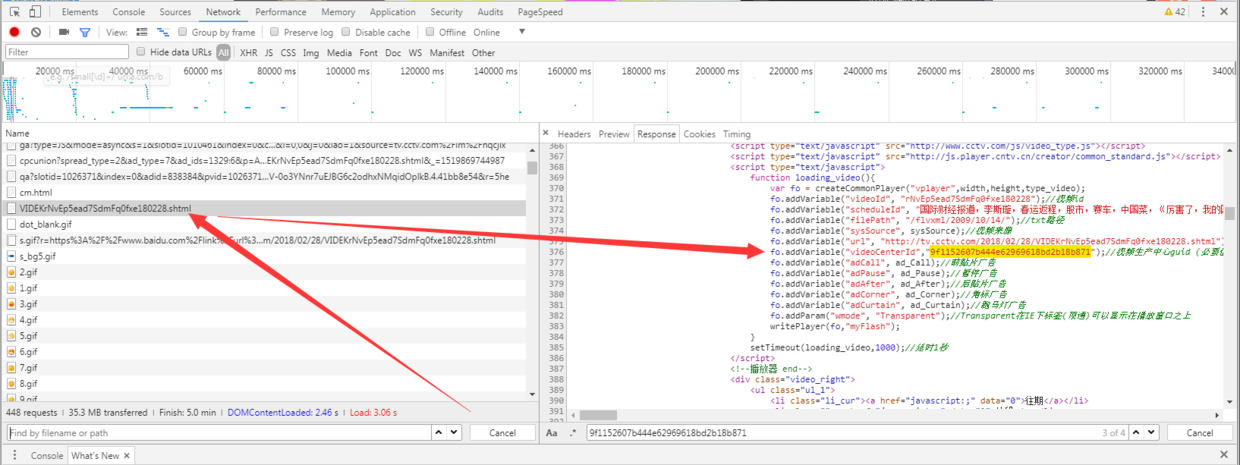
那么只要能够模拟访问
http://tv.cctv.com/2018/02/28/VIDEKrNvEp5ead7SdmFq0fxe180228.shtml #当前页面链接我们就能够找到节目码实现爬取视频了。
笔者一开始的思路是直接到http://tv.cctv.com/lm/hqcjlx/专题页面爬取最新节目的链接就好了,但是发现专题页面的更新有延迟(新节目可以在详细界面的往期模块看到,但是专题页面没有)并且偶尔会出现乱序的情况。所以最终Pass了这套方案,那么我们到哪里获取最新节目的链接呢?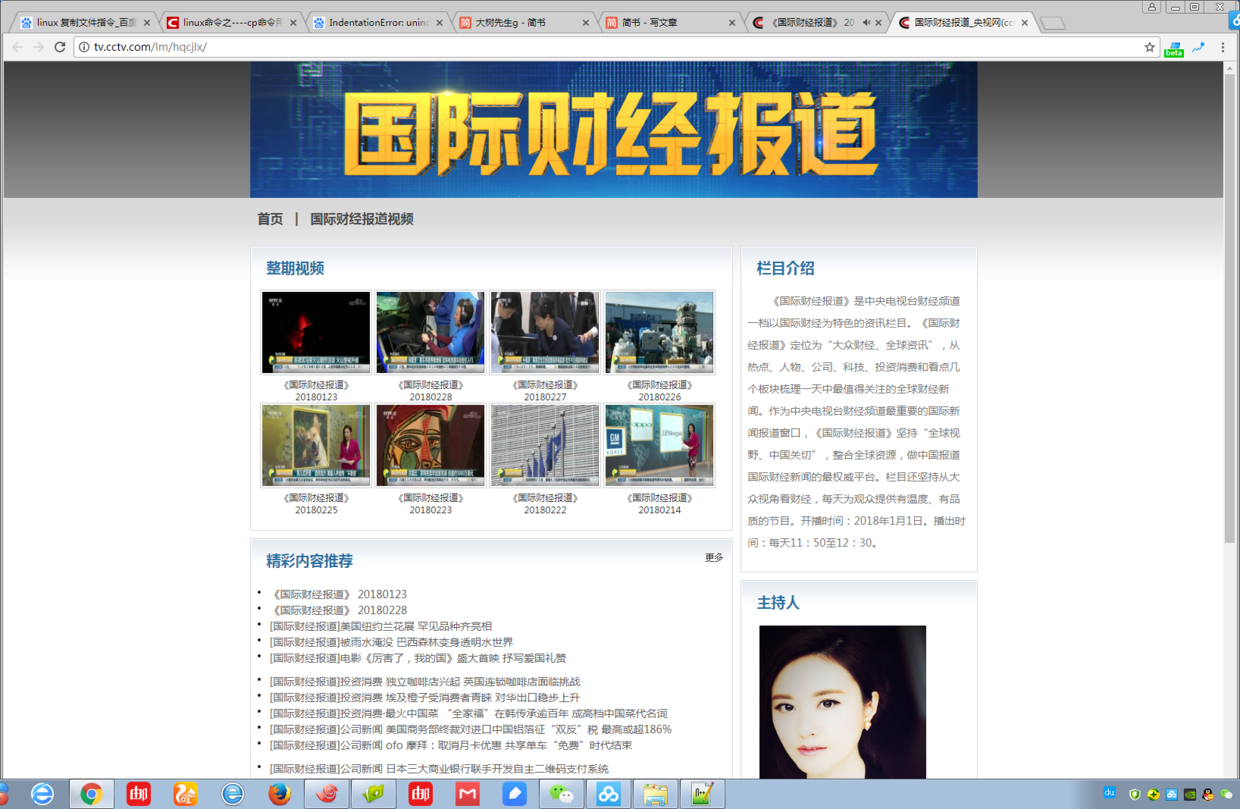
- 刚刚有提到,节目会最早更新在详细播放页面的往期中,我们只要爬到往期中的url链接就可以了。继续分析页面请求
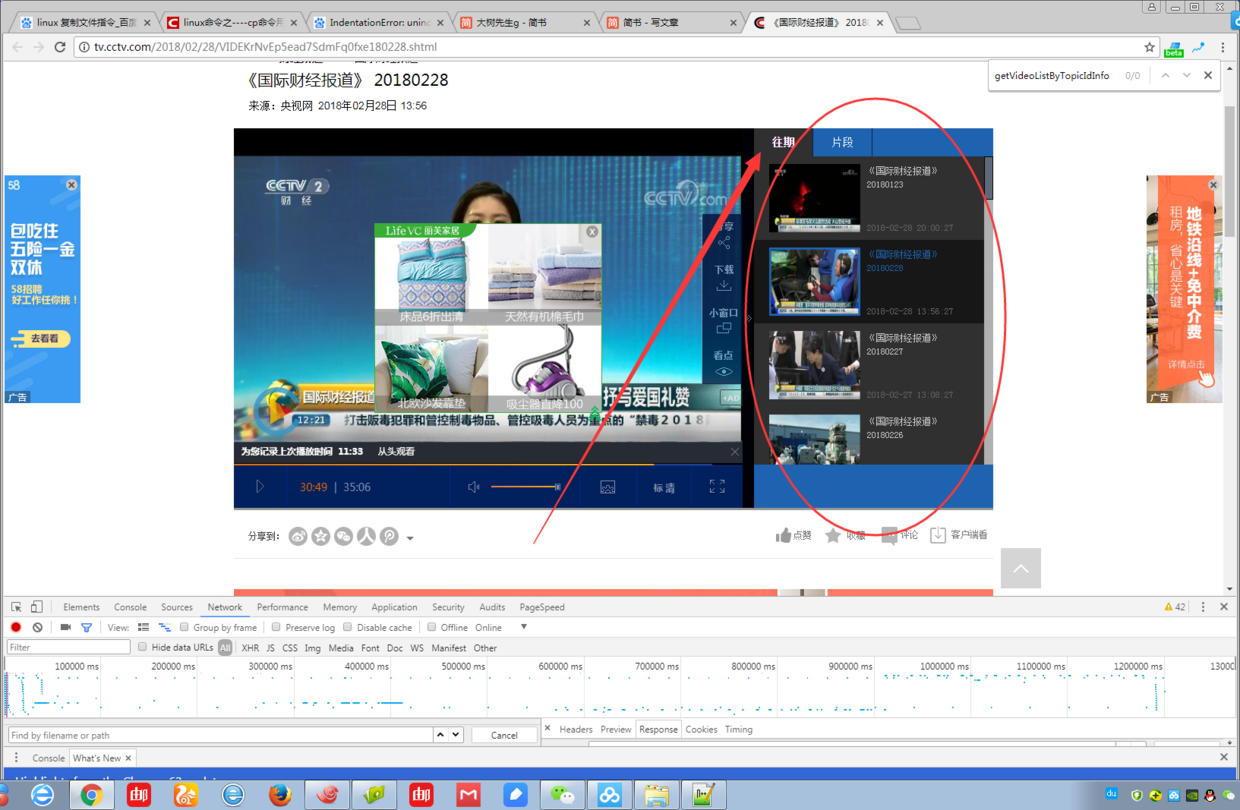
定位到接口http://api.cntv.cn/video/getVideoListByTopicIdInfo?videoid=VIDEKrNvEp5ead7SdmFq0fxe180228&topicid=TOPC1451531385787654&serviceId=cbox&type=0&t=jsonp&cb=setItem0=,返回了整个往期列表内的信息,分析关键参数videoid=VIDEKrNvEp5ead7SdmFq0fxe180228topicid=TOPC1451531385787654
只要能够获取到这两个参数,我们就可以发送往期视频接口列表的请求。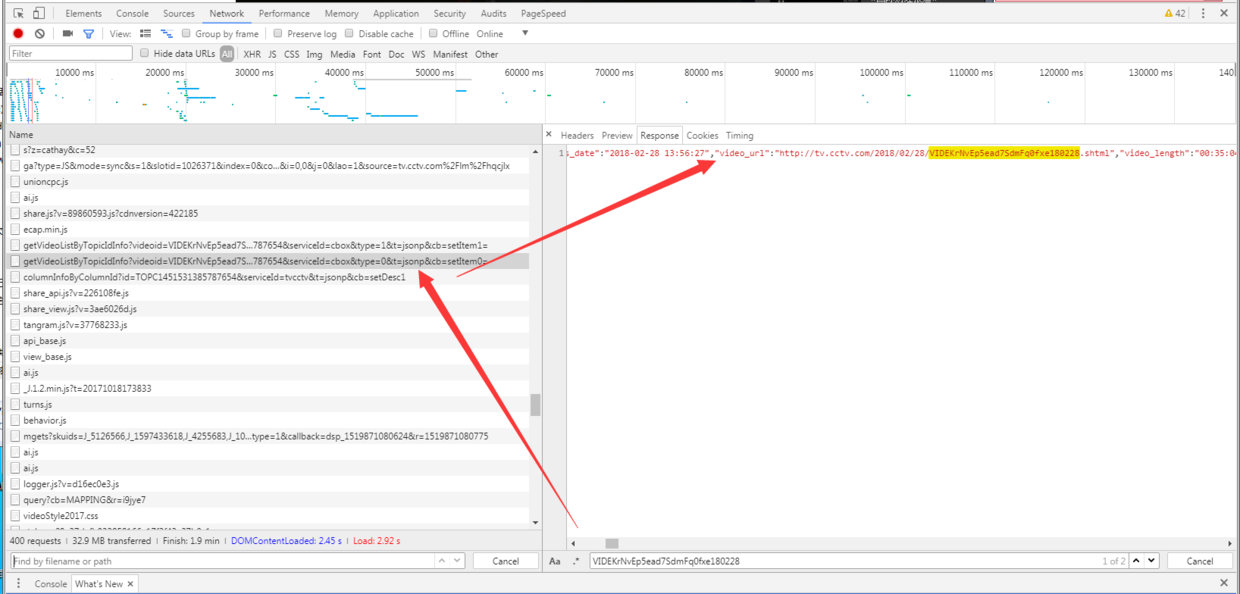
分析videoid和topicid
分析请求后看到,在页面请求中,我们在当前页面请求http://tv.cctv.com/2018/02/28/VIDEKrNvEp5ead7SdmFq0fxe180228.shtml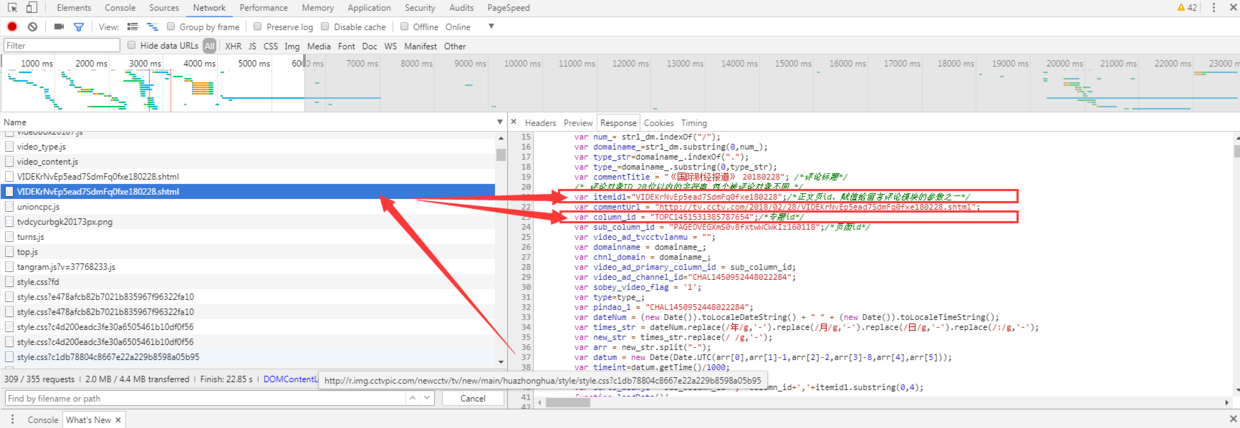
1
2
3var itemid1="VIDEKrNvEp5ead7SdmFq0fxe180228";/*正文页id,赋值给留言评论模块的参数之一*/
var column_id = "TOPC1451531385787654";/*专题id*/下面我们只要拿到最近任意一期的节目播放url,就可以拿到videoid和topicid了

分析的工作终于渐入尾声,我们来整理一下捋出的线
| 步骤 | 描述 |
|---|---|
| 1. 视频下载 | 为了实现视频下载,我们需要知道下载链接http://cntv.hls.cdn.myqcloud.com/asp/hls/850/0303000a/3/default/9f1152607b444e62969618bd2b18b871/4.ts中的节目码 |
| 2. 获取节目码 | 当前页面请求http://tv.cctv.com/2018/02/28/VIDEKrNvEp5ead7SdmFq0fxe180228.shtml返回了我们需要的节目码,获取节目最新节目链接 |
| 3.获取最新节目链接 | 节目接口http://api.cntv.cn/video/getVideoListByTopicIdInfo?videoid=VIDEKrNvEp5ead7SdmFq0fxe180228&topicid=TOPC1451531385787654&serviceId=cbox&type=0&t=jsonp&cb=setItem0=返回了我们需要的最新节目链接,但是要知道videoid和topicid |
4. 获取videoid和topicid |
在最近任意一期的节目页面请求中http://tv.cctv.com/2018/02/28/VIDEKrNvEp5ead7SdmFq0fxe180228.shtml我们可以获取videoid和topicid |
| 5. 获取最近一期节目链接 | 我们在专题页面http://tv.cctv.com/lm/hqcjlx/随便拿一期节目链接即可 |
至此,我们通过这条线就能够下载节目视频了
2. 视频下载
视频的下载可以查读代码,下载成功之后我们就会有一个有一个连续的.ts视频文件了1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126import requests
import re
import os
import time
import datetime
import hebingshipin
# 设置文件保存根目录
# path = r'E:\xn\开发\python\pythondown_yangshi'
path = r'/home/gzyDesktop/yangshiPython/huanqiucaijinglianxian/output/ts'
# 获取当前日期
now = datetime.datetime.now()
year = (now.strftime('%y'))
month = (now.strftime('%m'))
day = (now.strftime('%d'))
# print(year,month,day)
def getVideo():
videoCenterId = getVideoCenterId()
if (videoCenterId == "300"):
print("今日节目未更新,等待下次监测")
return "300"
else:
print("今日节目已更新,监测是否下载")
downloadVideo(videoCenterId)
# 根据videoCenterId将对应日期的节目下载到指定文件夹
def downloadVideo(videoCenterId):
filepath = path+r'/20'+year+month+day
isExists = os.path.exists(filepath)
if not isExists:
# 如果不存在则创建目录
# 创建目录操作函数
print("节目未下载,正在创建文件夹")
os.makedirs(filepath)
print('文件夹'+filepath + ' 创建成功')
print("正在下载视频")
# 下载文件
for i in range(1, 156):
downloadUrl = r'http://cntv.hls.cdn.myqcloud.com/asp/hls/850/0303000a/3/default/'+videoCenterId+r'/' + str(i) + r'.ts'
url = downloadUrl
r = requests.get(url)
with open(filepath + r'/'+year+month+day+r'_' + str(i).zfill(3) + r".ts", "wb") as code:
code.write(r.content)
print("视频下载成功")
print("正在将视频转为acc音频文件...")
hebingshipin.getMusic();
else:
# 如果目录存在则不创建,并提示目录已存在
print("视频已下载")
# 获取《环球财经连线最新节目的url》
def getVideoCenterId():
#
# 《环球财经连线》介绍页面
jieshaoyeurl = "http://tv.cctv.com/lm/hqcjlx/"
response = requests.get(jieshaoyeurl)
# 介绍页当前第一个节目的链接正则
firsturlCompile = '\"><a href=\"(.*?)\" target=\"_blank\">'
pattern = re.compile(firsturlCompile, re.DOTALL)
items = re.findall(pattern, response.text)
# print(items[0])
firsturl = items[0]
#
# 访问获取到的播放页面
response = requests.get(firsturl)
# column_id正则
column_idCompile = 'var column_id = \"(.*?)\";'
# itemid1正则
itemid1Compile = 'var itemid1=\"(.*?)\";'
column_idpattern = re.compile(column_idCompile, re.DOTALL)
column_iditems = re.findall(column_idpattern, response.text)
column_id = column_iditems[0]
# print(column_id)
itemid1pattern = re.compile(itemid1Compile, re.DOTALL)
itemid1items = re.findall(itemid1pattern, response.text)
itemid1 = itemid1items[0]
# print(itemid1)
#
# 由于介绍页面的节目不是最新节目,我们要调用另一个接口去获取最新的节目单
# http://api.cntv.cn/video/getVideoListByTopicIdInfo?videoid={itemid1}&topicid={column_id}&serviceId=cbox&type=0&t=jsonp&cb=setItem0=
jiemudanUrl = r'http://api.cntv.cn/video/getVideoListByTopicIdInfo?videoid=' + itemid1 + r'&topicid=' + column_id + r'&serviceId=cbox&type=0&t=jsonp&cb=setItem0='
response = requests.get(jiemudanUrl)
# 最新节目url正则
newJiemuCompile = 'video_url\":\"(.*?)\",'
newJiemupattern = re.compile(newJiemuCompile, re.DOTALL)
newJiemuitems = re.findall(newJiemupattern, response.text)
# print(response.text)
newJiemu = newJiemuitems[0]
# print(newJiemu)
#
#至此最新节目的url已经获取到了
#
#判断当前节目是否是最新节目,如果不是则return
if(newJiemu.find(day+".shtml") == -1):
return "300"
#
# 获取最新节目的videoCenterId,用于后续的下载
response = requests.get(newJiemu)
# 最新节目url正则
videoCenterIdCompile = r'addVariable\("videoCenterId","(.*?)"\);'
videoCenterIdpattern = re.compile(videoCenterIdCompile, re.DOTALL)
videoCenterIditems = re.findall(videoCenterIdpattern, response.text)
videoCenterId = videoCenterIditems[0]
# print(videoCenterId)
return videoCenterId
二、视频的合并与转码
视频的合并使用了ffmpeg,下载和安装可以参考 Centos 7.3 Install ffmpeg 3.11
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44def hebingshipin(inVideopath,outVideopath,outFilename):
mkdir(inVideopath)
mkdir(outVideopath)
dirs = inVideopath
mp4 = outVideopath
filename = outFilename
a = 1
content = ""
lists = os.listdir(dirs)
lists.sort()
print(lists)
b = [lists[i:i + 250] for i in range(0, len(lists), 250)]
for lis in b:
cmd = "cd %s && ffmpeg -i \"concat:" % mp4
for file in lis:
if file != '.DS_Store':
file_path = os.path.join(dirs, file)
cmd += file_path + '|';
# print("文件:%s"%file_path)
cmd = cmd[:-1]
cmd += '" -bsf:a aac_adtstoasc -c copy -vcodec copy %s.mp4' % a
try:
os.system(cmd)
content += "file '%s.mp4'\n" % a
a = a + 1
except:
print("Unexpected error")
fp = open("%smp4list.txt" % mp4, 'a+')
fp.write(content)
fp.close()
mp4cmd = "cd %s && ffmpeg -y -f concat -i mp4list.txt -c copy %s" % (mp4, filename)
os.system(mp4cmd)
filenamecmd = "cd %s && mv 1.mp4 %s" % (mp4, filename)
os.system(filenamecmd)
def mkdir(filepath):
isExists = os.path.exists(filepath)
if not isExists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(filepath)
else:
print(filepath+'文件夹已建立')
三、将视频转换为音频
1 | def videoToaacmusic(videoFilepath,videoFilename,musicFilename): |
总结:大概花了一天时间实现了这个想法,都是一些非常成熟的技术,重点在一整条链路的分析上,由于笔者是性能测试工程师,时常接触这方便的内容,且使用了其他工具,所以较为熟练。存在的疑点为:python爬虫的分析,目前是否存在相关的插件,可以帮助分析出一整条链路?