
- 环境准备
- Hadoop下载、配置、启动
- 参考链接
http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.7.0/hadoop-project-dist/hadoop-common/SingleCluster.html
环境准备
- 文件夹创建
1
2
3
4
5
6mkdir software # 存放所使用的软件安装包
mkdir app # 存放课程中所有软件的安装目录
mkdir data # 存放课程中使用的数据
mkdir lib # 存放课程中开发过的作业jar存放的目录
mkdir shell # 存放课程中相关的脚本(提交MapReduce和hive作业)
mkdir maven_resp # 存放课程中使用到的maven文件目录
安装JDK
1
2
3
4
5
6
7
8
9
10
11*****https://wiki.apache.org/hadoop/HadoopJavaVersions*******
jdk的选用先参照官网提示,部分jdk会存在缺陷
https://www.oracle.com/technetwork/java/javase/downloads/
tar -zxf jdk-8u171-linux-x64.tar.gz -C ../app/
把bin目录配置到系统环境变量(~/.bash_profile)中
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_51
export PATH=$JAVA_HOME/bin:$PATH
source ~/.bash_profile
java -version进行校验机器参数设置
1
2
3
4
5
6
7修改机器名: /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=hadoop001
设置ip和hostname的映射关系: /etc/hosts
192.168.199.200 hadoop001
127.0.0.1 localhostssh免密码登录,用于多集群之间的登录
1
2
3
4
5
6
7
8
9
10
11host1---->host2
进入host1机器
cd ~/.ssh
ssh-keygen -t rsa(四个回车)
ssh-copy-id host2(输入密码,大功告成)
ssh host2
这里我们配置本机的互信
多机器之间的互信可以参考:
伪分布式下载配置
下载hadoop并解压
1
2
3
4
5
6http://archive.cloudera.com/cdh5/cdh/5/
这里我们使用的版本为:2.6.0-cdh5.7.0
cd app
wget http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.7.0.tar.gz
tar -zxf hadoop-2.6.0-cdh5.7.0.tar.gz -C ../app/Hadoop文件夹介绍·
1
2
3
4
5
6
7
8
9
10
11
12bin:存放hadoop、hdfs、yarn客户端程序
bin-mapreduce1
cloudera
etc/hadoop:配置文件相关
examples
examples-mapreduce1
include
lib
libexec
sbin:服务相关hdfs,yarn启动
share:常用例子
src配置hadoop环境变量
1
2export HADOOP_HOME=/root/app/hadoop-2.6.0-cdh5.7.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH\配置文件修改(修改jdk位置、hadoop端口、副本数、tmp目录地址)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28hadoop-env.sh
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_51
# 这里需要配置我们的任务pid保存路径,一定要与下面的hdfs-site.xml保持一致
export HADOOP_PID_DIR=/home/hadoop/app/tmp
export HADOOP_SECURE_DN_PID_DIR=/home/hadoop/app/tmp
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:8020</value>
</property>
hdfs-site.xml
# 配置副本系数
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
# 设置tmp文件存储目录,避免tmp文件重启时被清空
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/tmp</value>
</property>
slaves
hadoop001第一次启动hadoop
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22第一次启动HDFS的时候要格式化文件系统
进入bin目录
hdfs namenode -format
信息如下时代表成功
19/01/15 02:27:47 INFO common.Storage: Storage directory /root/app/tmp/dfs/name has been successfully formatted.
进到sbin目录下
./start-dfs.sh
jps存在对应进程时代表服务启动成功
[root@hadoop001 sbin]# jps
8528 SecondaryNameNode
8371 DataNode
8661 Jps
8255 NameNode
查看防火墙状态:sudo firewall-cmd --state
关闭防火墙: sudo systemctl stop firewalld.service
禁止防火墙开机启动:systemctl disable firewalld or chkconfig iptables offHadoop浏览器界面访问
XXXX:50070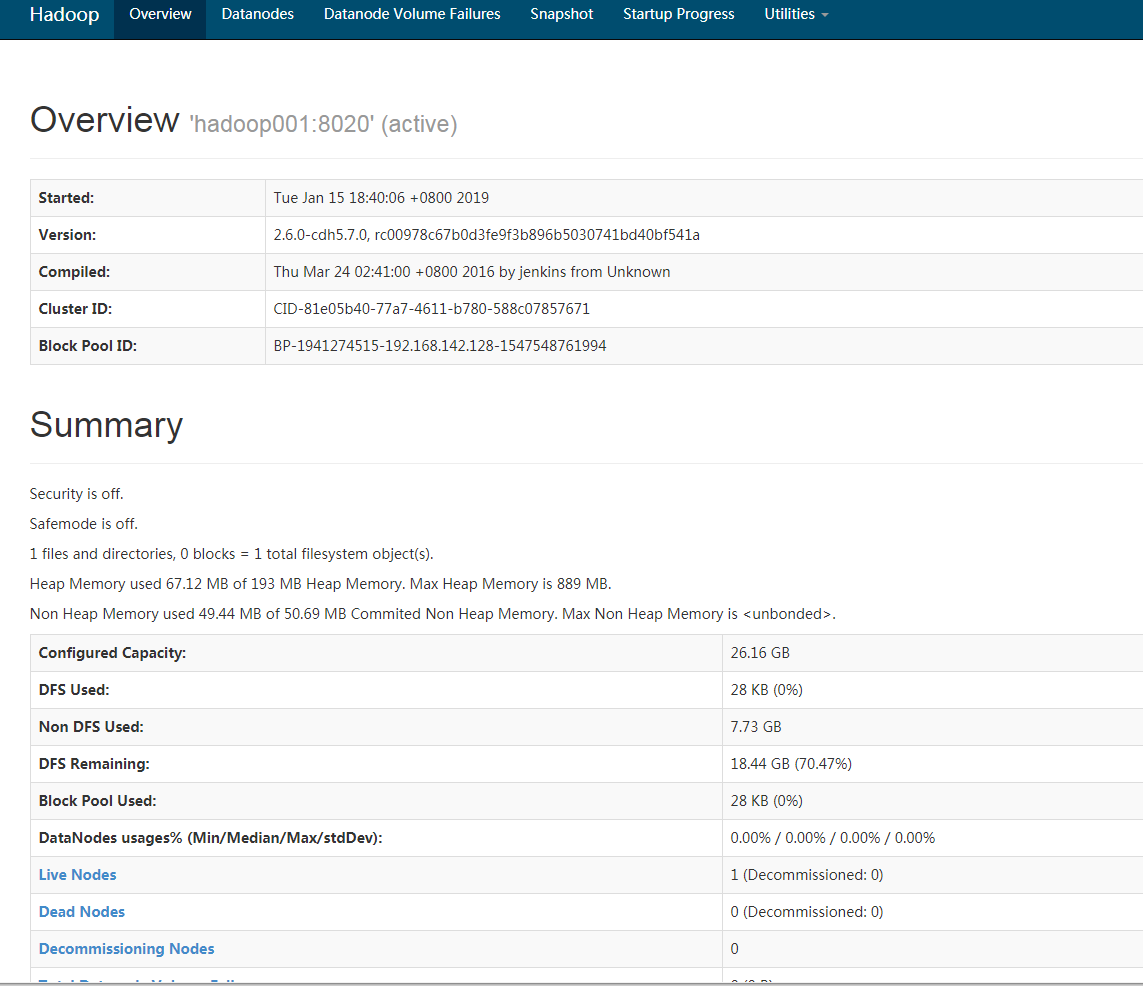
yarn的启动与配置
mapreduce配置文件修改
1
2
3
4
5
6
7
8
9
10
11
12etc/hadoop/mapred-site.xml:
这里由于默认是没有这个文件,只有template 文件,所以需要cp一下
cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>yarn配置文件修改
1
2
3
4
5
6
7
8
etc/hadoop/yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>启动yarn进程
1
2
3
4
5sbin/start-yarn.sh
jps查看可以看到
23616 ResourceManager
23706 NodeManager浏览器窗口
http://hadoop001:8088/cluster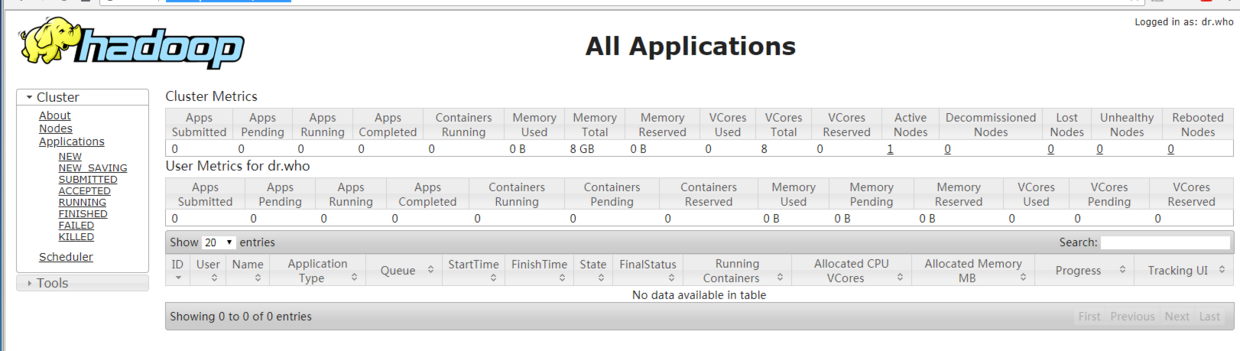
日志文件查看
1 | logs/xxx |