
写流程
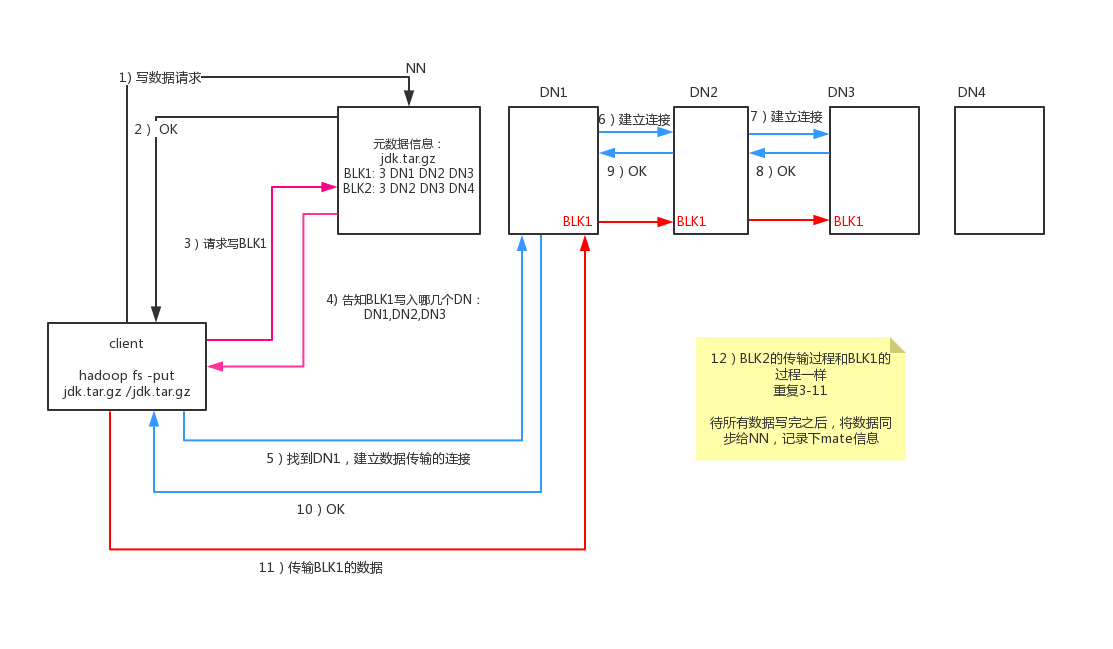
1 | client端执行hadoop fs -put jdk.tar.gz /jdk.tar.gz 2block,3副本 |
读流程
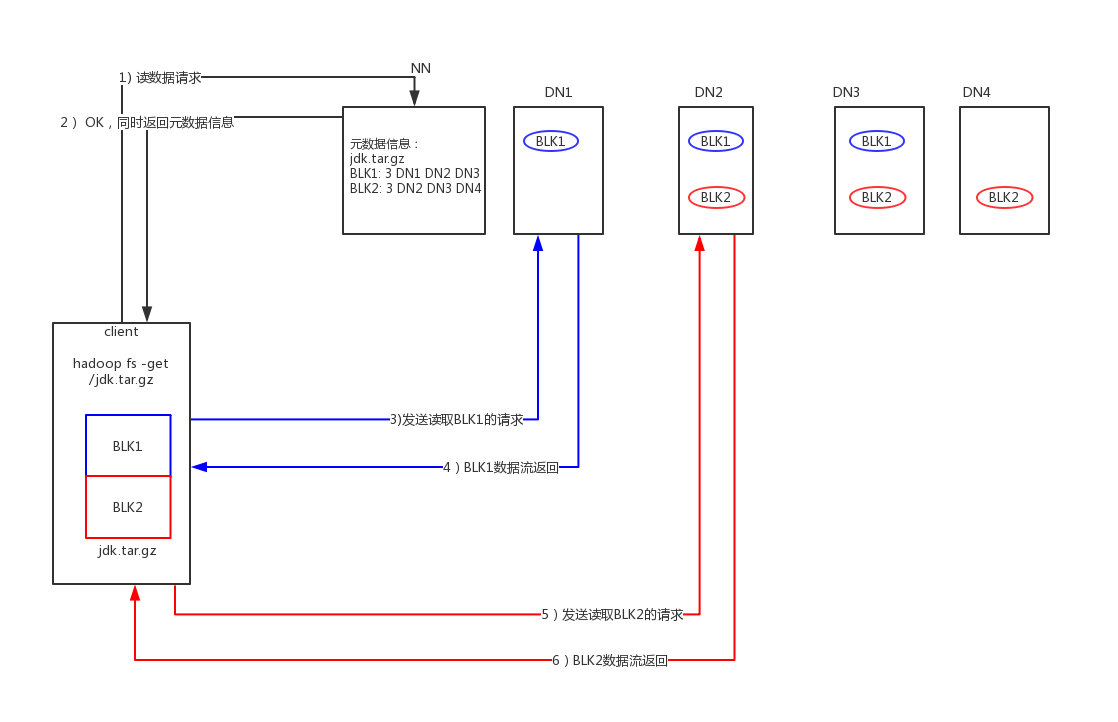
1 | 1、 读数据请求 |
多副本放置顺序
副本顺序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15第一个副本:放置在上传的DN节点上
如果是集群外提交,则随机挑选一台磁盘不太慢,CPU不太忙的节点上
DN节点提交-->放置在上传的DN节点上
集群外提交-->由DN判断随机挑选一台磁盘不太慢,CPU不太忙的节点上
第二个副本:
放置在第一个副本的不同的机架的节点上
第三个副本:
与第二个副本相同的不同节点上
假如还有更多的副本:随机放
生产上尽量在DN节点上进行读写动作,可以减少网络带宽机架放置机器的计算
1
机架支持的总电源/每台机器占用的电源=机器