
为什么要HA部署
- 如果HDFS和YARN的master宕机,整个服务就挂掉了
1
2
3
4
5
6
7
8
9
10
11HDFS:
NN master
SNN
DN
YARN:
RM master
NM
- 小拓展
hbase的读写是不需要经过master的,只有建表删表才会走master
1 | 由于SNN是1小时的checkpoint机制,不能做到完全的高可用,所以有了我们的HA架构 |
HA理论
思想
1
2
3
4
5
6部署两个NN节点
- 任何时候只有1台active对外
- 另外一台是standby状态,实时备份
NN1 ACTIVE
NN2 STANDBY命名空间
1
2
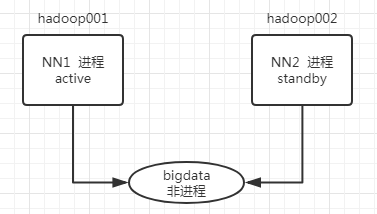
3由于部署了两台NN的原因,但是我们的shell脚本和程序是需要填入对应的NN的ip的,所以就有了命名空间的概念
我们可以通过命名空间连接NN,但是我们不知道是哪台NN给我们提供的服务
1
2
3
4- 当我们发起hdfs://bigdata/user/请求时
- 会按照配置文件(这里假设NN2配置在先)先请求NN2
- 发现NN2是standy进程,会再去请求NN1进程
- 发现NN1是active节点,接收请求并执行
HA进程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
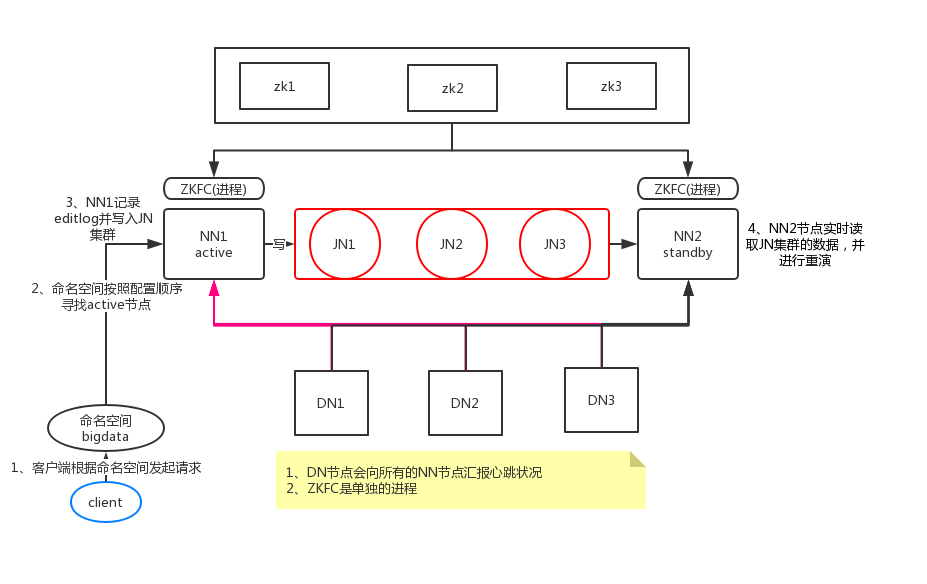
173台机器
hadoop001:ZK ZKFC NN JN DN
hadoop002:ZK ZKFC NN JN DN
hadoop003:ZK ZKFC JN DN
NN:fsimage editlog(读写请求记录)
ZK(2n+1 奇数台):负责选举,决定active和standby在哪台节点
ZKFC(zookeeperFailOverControl):节点真正挂掉,负责将standy状态的节点激活的进程
JN:同步editlog的进程
zk节点可以参照下面的数量
20台节点:5台
20~100台节点:7/9/11台
>100台:11台
由于active节点挂掉时其他节点要进行选举,所以并不是节点越多越好部署架构图
解释及重点
1
2
3
4
5
6
7
8
9- 流程
- 1、客户端根据命名空间发起请求
- 2、命名空间按照配置顺序寻找active节点
- 3、NN1记录editlog并写入JN集群
- 4、NN2节点实时读取JN集群的数据,并进行重演
- 重点
- 1、DN节点会向所有的NN节点汇报心跳状况
- 2、ZKFC是单独的进程补充:HA是为了解决单点问题,监控状态,自动备援
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20JN集群:
- 共享状态
- 用于active standby节点的数据同步
- 一般部署2n+1个
ZKFC:选举active机器
- 单独进程
- 监控NN健康状况
- 向ZK集群定期发送心跳,使得自己可以被选举
- 当自己被ZK选举为active的时候,zkfc进程通过RPC协议调用使NN节点的状态变为active,对外提供服务,这个过程是无感知的
ACTIVE NN:
- 操作记录写到自己的editlog
- 同时写JN集群
- 接收DN的心跳和块报告
standby NN:
- 同步接收JN集群的日志
- 显示读取执行log操作(重演),使得自己的元数据和active nn节点保持一致
- 接收DN的心跳和块报告